不写一行SQL也能让数据说话!如何用Vanna框架轻松解锁数据分析的未来?
from https://zhuanlan.zhihu.com/p/689794846
想快速从数据库拿到答案?Vanna框架让这变得简单。
这是一款开源的工具,帮你生成SQL,让数据自己说话。
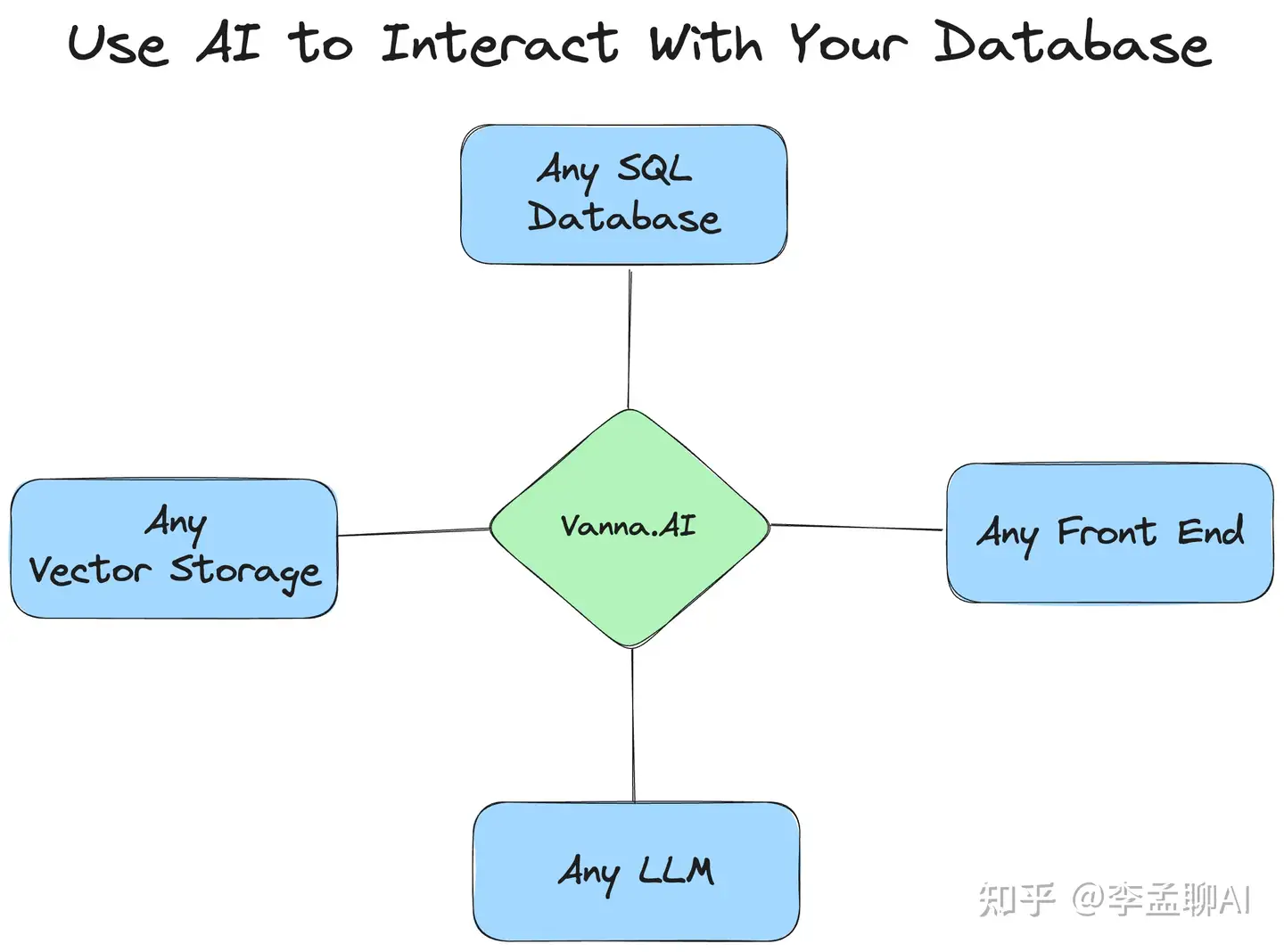
Vanna有三种模式,适应不同的需求。
第一种,开源模式。
你可以用它来集成任何你喜欢的语言模型,完全自定义。
就像自己搭积木,想怎么玩就怎么玩。
第二种,免费模式。
这里有日限额的模型使用,还有免费的存储服务。
用GPT 3.5,你可以不花一分钱就开始探索数据。
第三种,付费模式。
如果你需要更多,这里有无限制的使用,GPT-4的支持,还有服务保障。
想象一下,不管你是开发者还是分析师,都能用Vanna来发现数据的秘密。
那么,我们一起看下Vanna的工作原理和实现细节。
如何工作?
如果有个工具能让你像聊天一样和数据库交流,那会多方便。
Vanna就是这样一个Python包,它用RAG技术帮你快速生成SQL查询。
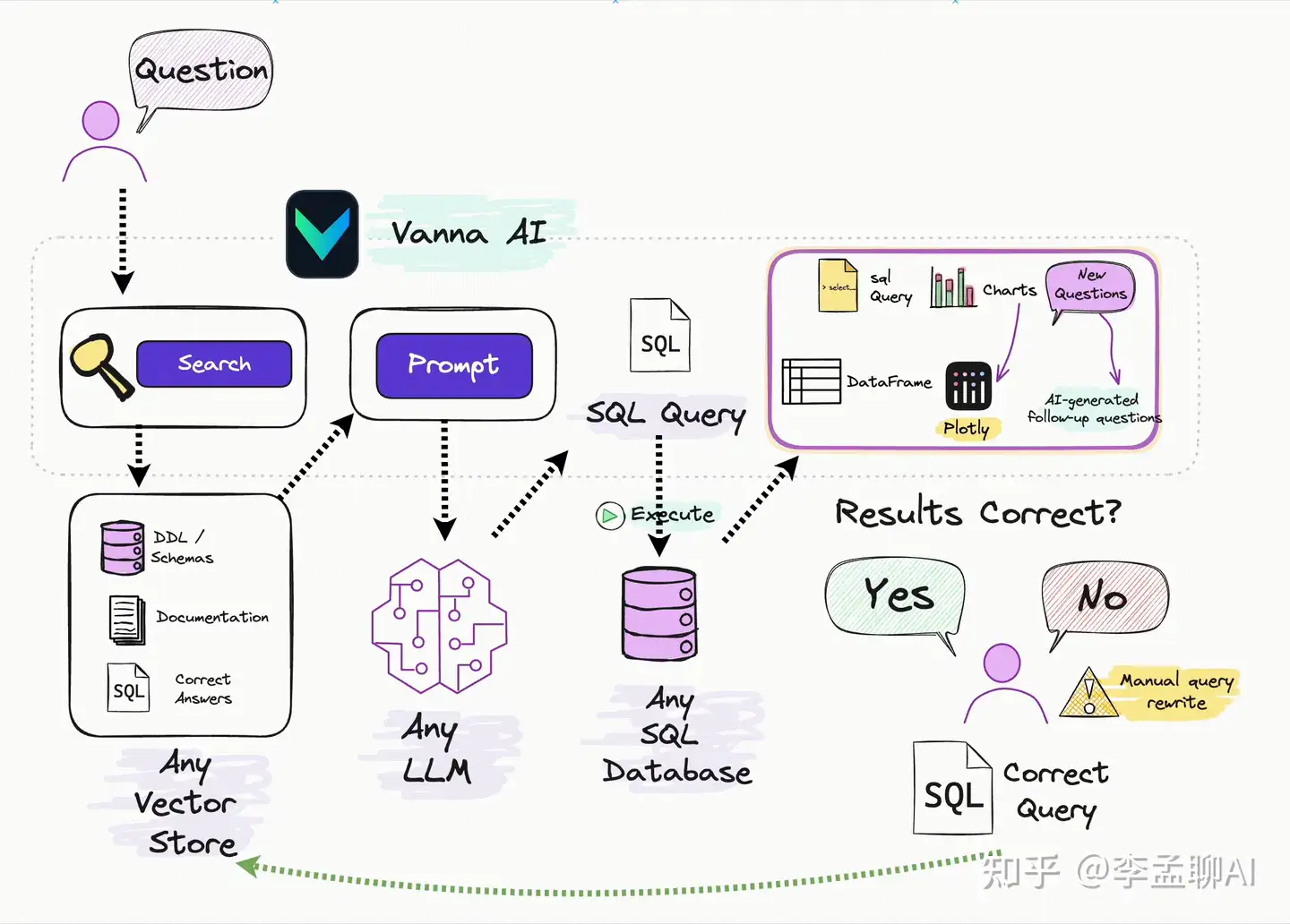
用Vanna就两步:
1.训练一个模型。
2.问问题,它回答SQL。
RAG技术就是找到和你问题相关的信息,然后生成答案。
你不用担心背后的技术细节,只需要知道它能帮你解决问题。
Vanna是开源的,你可以在自己服务器上用。
训练数据越多,Vanna处理数据的能力就越强。
安全性方面,Vanna很谨慎。
不会让你的数据随便出去,除非用到特定功能。
Vanna用得越多,它就越懂你。
因为它会学习你的数据,不断进步。
它支持很多数据库,比如Snowflake、BigQuery、Postgres。
还能为其他数据库创建连接器。
前端使用也灵活。
可以从Jupyter Notebook开始,或者用Slackbot、网页应用、Streamlit等。
甚至可以集成到你的网页应用里。
第一种,Vanna提供API快速开始
首先,去Vanna的官网,点击“Get Started for Free”。
https://vanna.ai/
接下来,你需要注册一个模型名称,这就像是给你的新伙伴起个名字。
然后,你会得到一个key,每天有100k的免费额度可以用。
接下来,运行代码启动平台。
这里有个小技巧,填写你注册账号时用的邮箱,然后输入验证码。
import vanna
from vanna.remote import VannaDefault
vn = VannaDefault(model='chinook', api_key=vanna.get_api_key('my-email@example.com'))
vn.connect_to_sqlite('https://vanna.ai/Chinook.sqlite')
vn.ask("What are the top 10 albums by sales?")
from vanna.flask import VannaFlaskApp
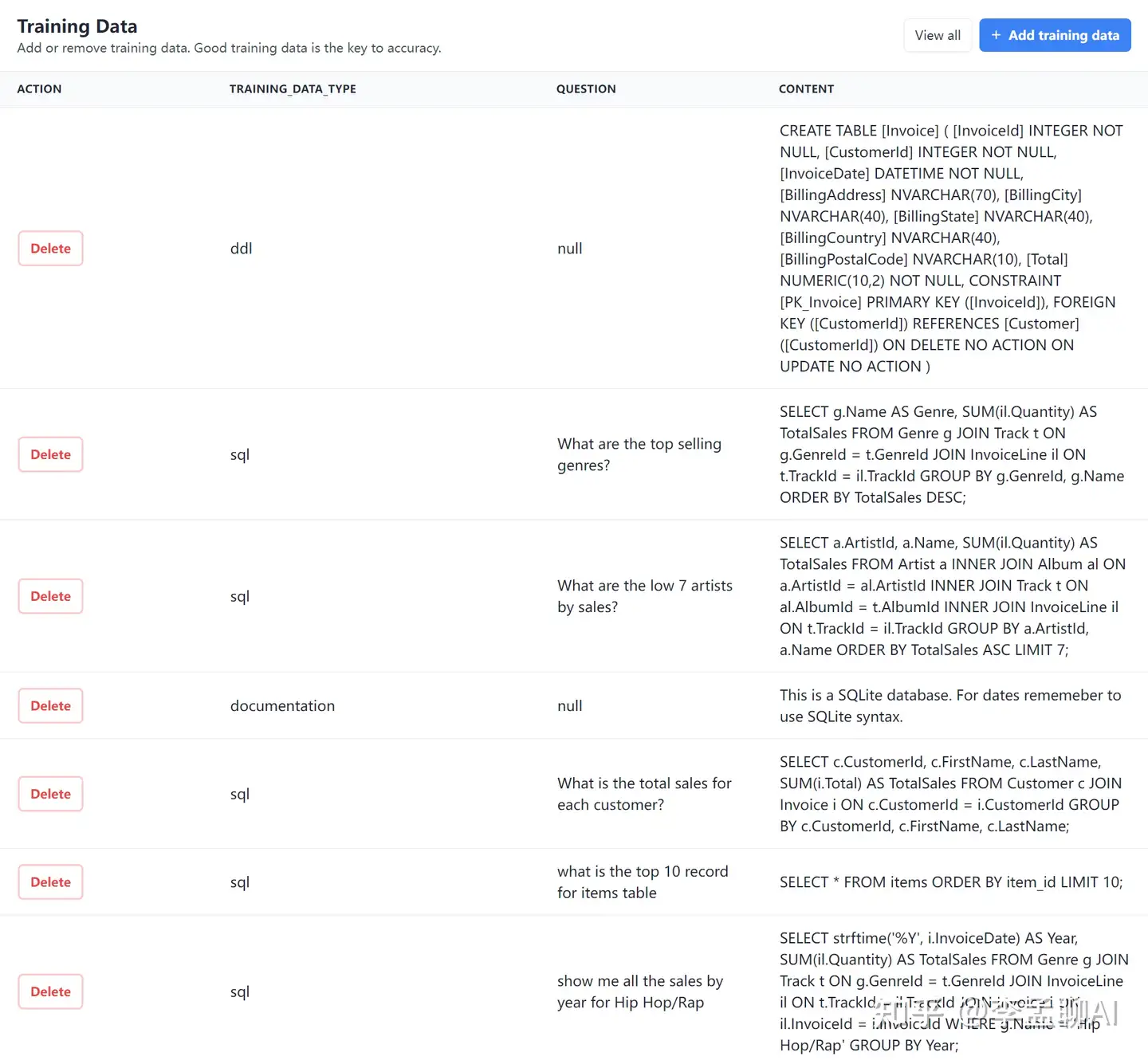
VannaFlaskApp(vn).run()Vanna已经为你准备了一些默认的训练数据,但如果你想,你也可以添加新的数据。
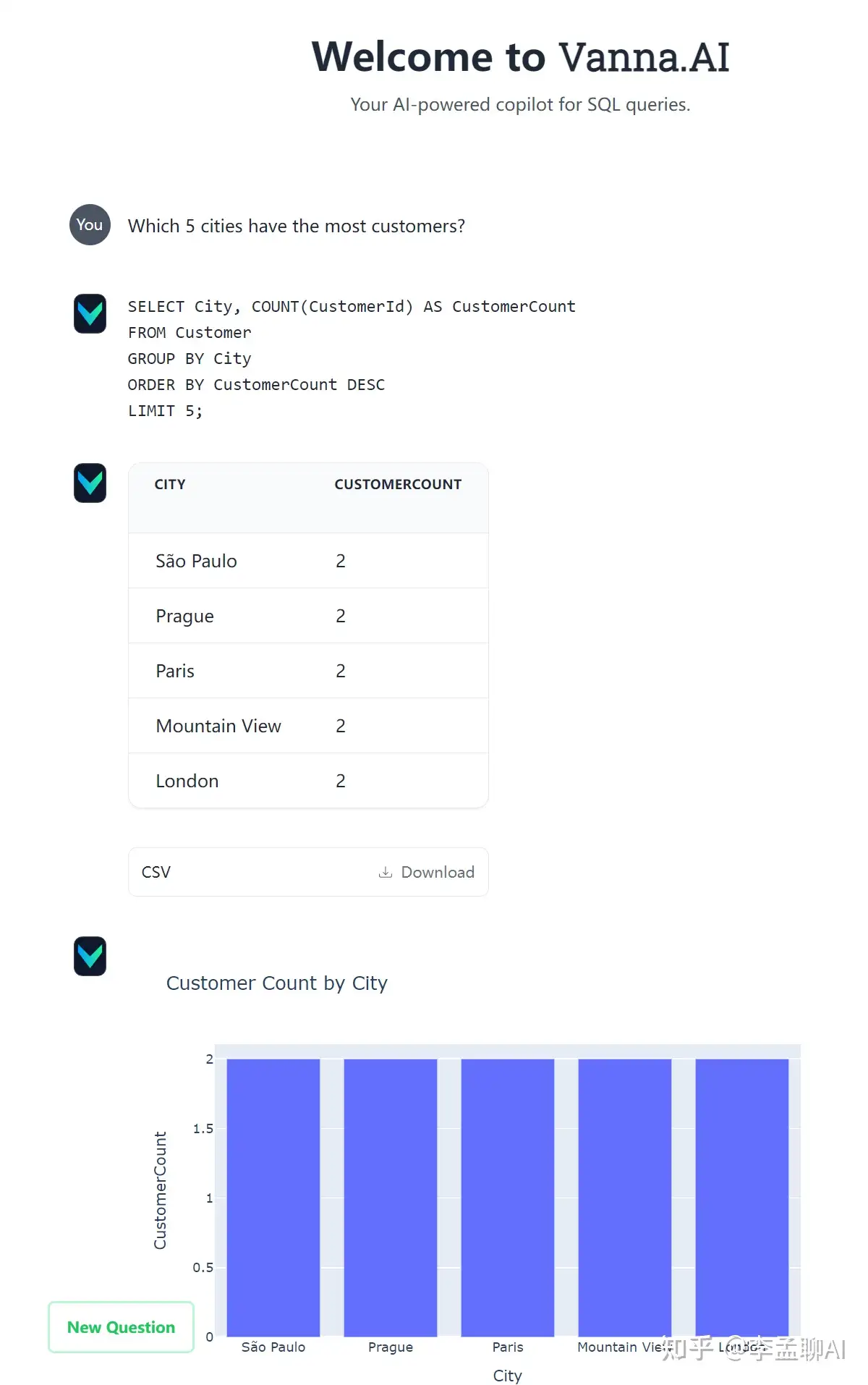
最后,当你输入提示词时,Vanna就会根据你的提示生成结果。
就像是你在和一个智能助手对话,它能理解你的需求并给出回应。
实现代码:https://colab.research.google.com/github/vanna-ai/notebooks/blob/main/app.ipynb
第二种,本地Vanna快速开始
这个方案可以让你免费使用很多模型,而且操作起来还很简单。
这个方案支持OpenAI、Anthropic、ollama等模型,你甚至可以自定义其他模型。
同时,它还支持多种向量库,包括在线的VectorDB。
用ChromaDB的开源向量数据库,完全免费,而且本地使用,不需要额外设置。
所有的数据库文件都会自动创建和存储在你的电脑上。
另外,你还可以选择Marqo,同样是本地免费使用,不过需要一些设置。
或者,你也可以使用他们提供的托管选项。
代码示例,我们可以用开源的ollama框架加上Vanna来实现一个SQL模型。
整个过程都是免费的,而且非常方便快捷。
如果你对ollama框架的安装还不太熟悉,可以参考我之前的文章。
安装好之后,你就可以在代码中加载模型了,记得这个模型必须是ollama已经预先加载过的。
接下来,你就可以运行下面的代码。
from vanna.ollama import Ollama
from vanna.chromadb.chromadb_vector import ChromaDB_VectorStore
class MyVanna(ChromaDB_VectorStore, Ollama):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
Ollama.__init__(self, config=config)
vn = MyVanna(config={'model': 'gemma:7b'})
vn.connect_to_sqlite('my-database.sqlite')
df_ddl = vn.run_sql("SELECT type, sql FROM sqlite_master WHERE sql is not null")
for ddl in df_ddl['sql'].to_list():
vn.train(ddl=ddl)
vn.train(ddl="""
CREATE TABLE IF NOT EXISTS my-table (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT
)
""")
vn.train(
documentation="Our business defines OTIF score as the percentage of orders that are delivered on time and in full")
vn.train(sql="SELECT * FROM my-table WHERE name = 'John Doe'")
training_data = vn.get_training_data()
from vanna.flask import VannaFlaskApp
VannaFlaskApp(vn).run()注意,这个过程可能需要等一会儿,因为你的模型需要根据SQL数据进行训练。
项目地址:https://github.com/vanna-ai/vanna
结语
就这样,我们一步步走过了Vanna的世界。
从简单的注册和启动,到和数据库聊天一样自然的对话,Vanna展示了它的力量和灵活性。
你可以选择开源模式,自由地搭建和定制;也可以选择免费模式,轻松上手,不花一分钱;当然,如果你的需求更高,付费模式也随时待命,提供无限制的使用体验和更强大的支持。
现在,想象一下,无论你在哪里,只需要几行代码,就能和你的数据“对话”。
这听起来是不是像是来自未来的技术?
但它已经在这里,等着你去探索。
作者 @李孟聊AI,独立开源软件开发者,SolidUI作者,对于新技术非常感兴趣,专注AI和数据领域。